第一次接触到服务端开发,应该是学 Java 的时候,了解到了 servlet 这么一个东西。在做 Java 的时候一直以来都是和 Tomcat, Jetty 这样的 Web 容器打交道。记得那段时间找到一本书《How Tomcat works》, 我花了两周时间阅读,感触良多。后来又陆陆续续接触到了 Netty 之类的。
我开始问自己,实现一个 http 服务器,到底需要做什么?
所以,直接上 C 吧。参照某个经典的案例。
首先在读源码之前,可以再温习一下基于 TCP 的协议是如何通信的。
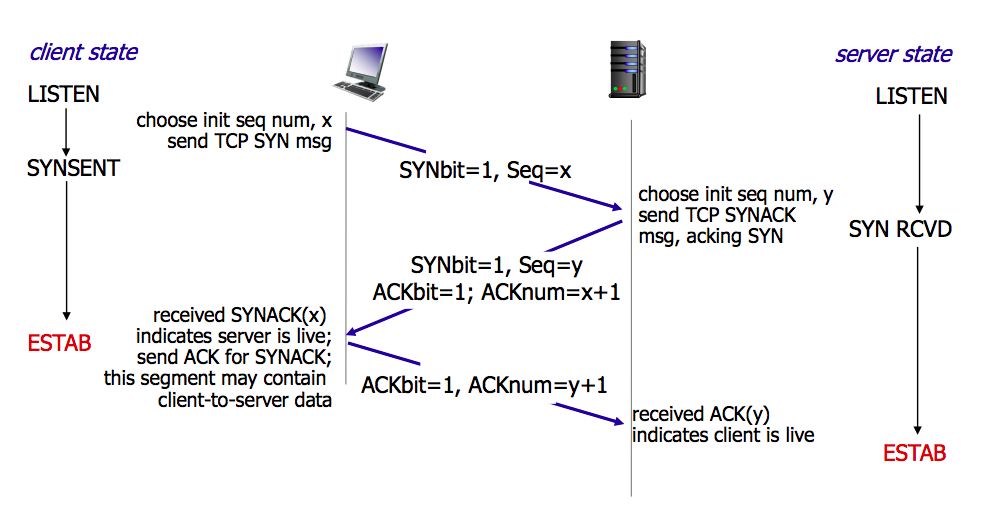
TCP
结合这个图,从源码的角度一步一步分析。源码地址 https://github.com/razertory/tinyhttpd
主流程
- 服务端初始化
- 等待客户端
- 连接,通信,结束通信,结束连接
1 | int main(void) |
启动一个 http server
- 调用库 socket() 函数产生 httpd
- 调用 bind() 函数让 socket 绑定给某个端口 (绑定过程比想象复杂)
- 调用 listen() 函数监听端口
1 | int startup(u_short *port) |
接受 & 解析请求
1 | void accept_request(int client) |
不需要 cgi 机制的 response
1 | void serve_file(int client, const char *filename) |
需要 CGI 机制的 response
1 | void execute_cgi(int client, const char *path, |
补充
CGI 机制
CGI 全称是 “通用网关接口”(Common Gateway Interface),它可以让一个客户端,从网页浏览器向执行在 Web 服务器上的程序请求数据。 CGI 描述了客户端和这个程序之间传输数据的一种标准。 CGI 的一个目的是要独立于任何语言的,所以 CGI 可以用任何一种语言编写,只要这种语言具有标准输入、输出和环境变量。 如 php,perl,tcl 等。
- 客户端访问某个 URL 地址之后,通过 GET/POST/PUT 等方式提交数据,并通过 HTTP 协议向 Web 服务器发出请求。
- 服务器端的 HTTP Daemon(守护进程)启动一个子进程。然后在子进程中,将 HTTP 请求里描述的信息通过标准输入 stdin 和环境变量传递给 URL 指定的 CGI 程序,并启动此应用程序进行处理,处理结果通过标准输出 stdout 返回给 HTTP Daemon 子进程。
- 再由 HTTP Daemon 子进程通过 HTTP 协议返回给客户端。